 Data Collection Automation
Data Collection AutomationIn a Market Where Being 3 Seconds Faster Wins
30-50% faster alerts with 0% message loss. Real-time monitoring of 100+ Korean e-commerce sites built for North America's leading cook group community.
When a site changes and collection stops, AI finds the cause and fixes it; a person only approves the change. AI takes over the work people used to do. The story of rebuilding a system that watched dozens of shopping sites 24/7 so it could run on its own.
The next wall of a custom crawler: every site change still needed a developer
This customer already ran a custom system watching dozens of Korean shopping sites (Nike, Musinsa, Adidas, and more) in real time. Alerting members about limited-edition drops and restocks faster than competitors, it was the customer's core system. The problem was operations. Shopping sites change their pages constantly, and each time collection quietly comes back empty. Only after someone noticed 'hey, no alerts are coming' would a staffer open the site, find what changed, fix it, check it, and bring it back up — again and again, every time a site changed.
At first, every new site meant copying a program and bolting it on. Past 30 sites and three servers, the upkeep grew. Each server ran dozens — nearly 70 programs in total — and when one stopped, someone had to see the alert and restart it by hand. When a site changed and collection broke, only the person who built that site could fix it, and that one person's time held everything back. A structure with less human dependence was needed.
“We had built the crawler itself well. But every time a site changed, a person still had to step in. Someone had to notice alerts weren't coming, a developer had to fix the code — and by then we were already late. We asked whether this could run without people.”
— Customer operations team
Replacing the human 'analyze → fix → test → deploy' loop with an AI Agent
The idea was simple: move the failure response people used to do into the system itself. When collection comes back empty several times in a row, the system declares a failure on its own, AI re-examines the site to find a fix and drafts the change, then asks a person only to approve. To get there, we first set the boundary AI could safely touch and pulled the per-site bits out of the program into separate 'settings.'
The first thing we changed was the only-a-human-can-fix-it structure. Each site used to have its collection method buried inside the program, so any change meant a developer opening the code. We moved that out into 'settings' outside the code. Now what to collect, and how, is decided in settings, not in the program — a safe surface for AI to touch, set up first.
This system doesn't run on one machine but across three servers. The strongest hub server carries 28 collectors plus alerts, self-recovery, and monitoring, while the other two run 22 and 20 collectors and send their results to the hub. Responsibilities are split so a problem on one server doesn't stop the whole thing.
← Scroll horizontally to view the chart
Three servers split the work — collection results and recovery signals converge on the hub
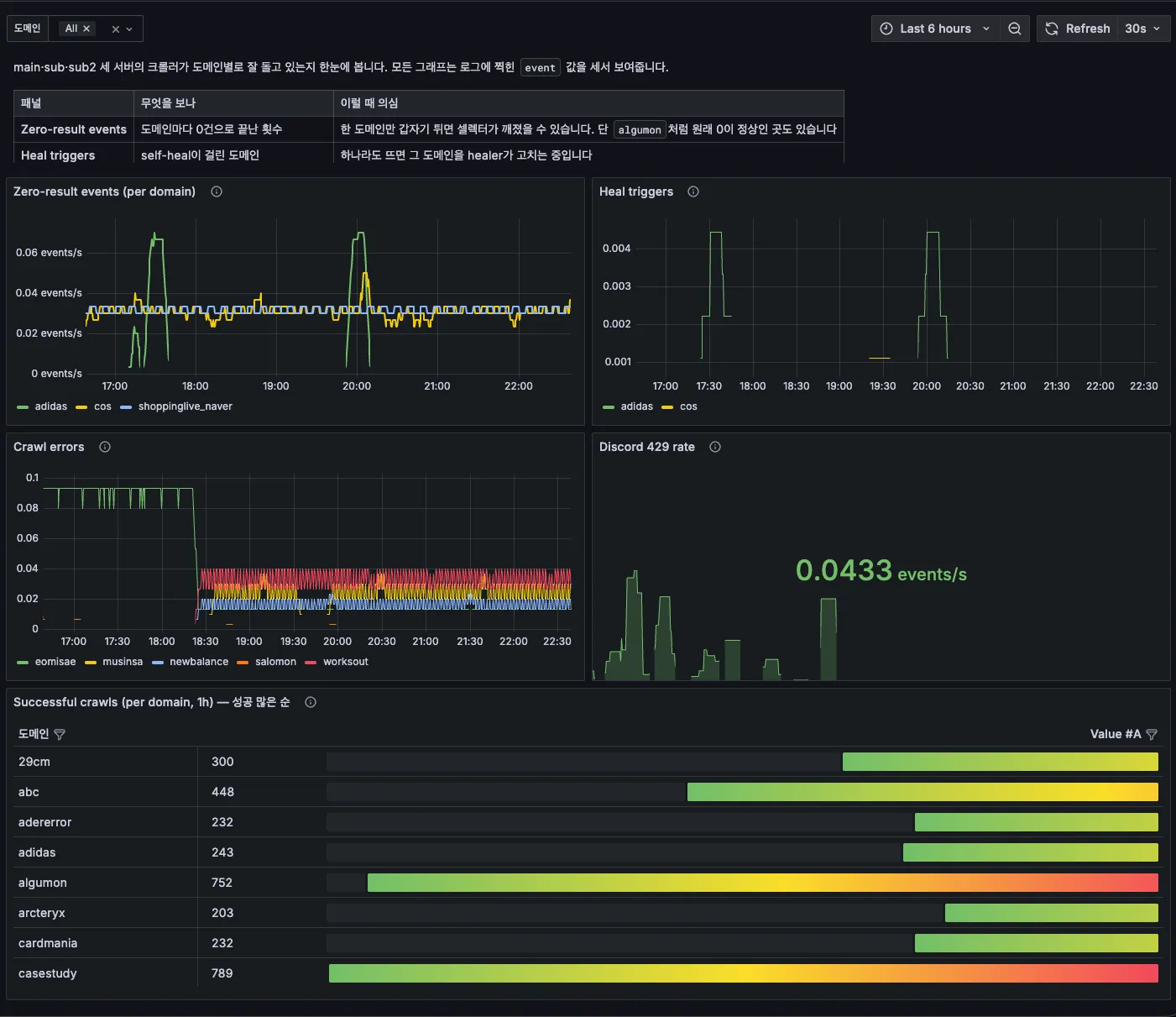
Dashboard — per-site collection status and auto-recovery events at a glance
On top of that we added a 'fixes itself' flow. When a site comes back empty several times in a row (five by default), the system treats it as a failure and first alerts the ops channel: 'collection on site X is broken.' It usually takes just a few minutes — the system raises its hand before a person even notices.

An automatic warning to the ops channel the moment collection breaks — the system reports before anyone notices
It doesn't stop at alerting. AI doesn't fix by guessing. It goes into the site itself to see how the page changed and whether there's a faster, more reliable way to get the data, then re-tunes the collection settings the best way it can. It does what a human would during an incident — except it doesn't wait for a person, starting at midnight or on a weekend all the same.
What we cared about most was keeping AI's fixes from reaching production carelessly. A fix AI makes must first pass an automatic check. On pass, it only files a review request saying 'here's how I fixed it' — it never goes straight to production. We built both a fully automatic path that runs from detection to review request with no human touch, and a semi-automatic path an operator starts with one button. Either way, a human makes the final call. If fixes keep failing, it stops at a set limit and calls a person.
← Scroll horizontally to view the chart
A fix becomes a review request only after passing the automatic check — a human decides production
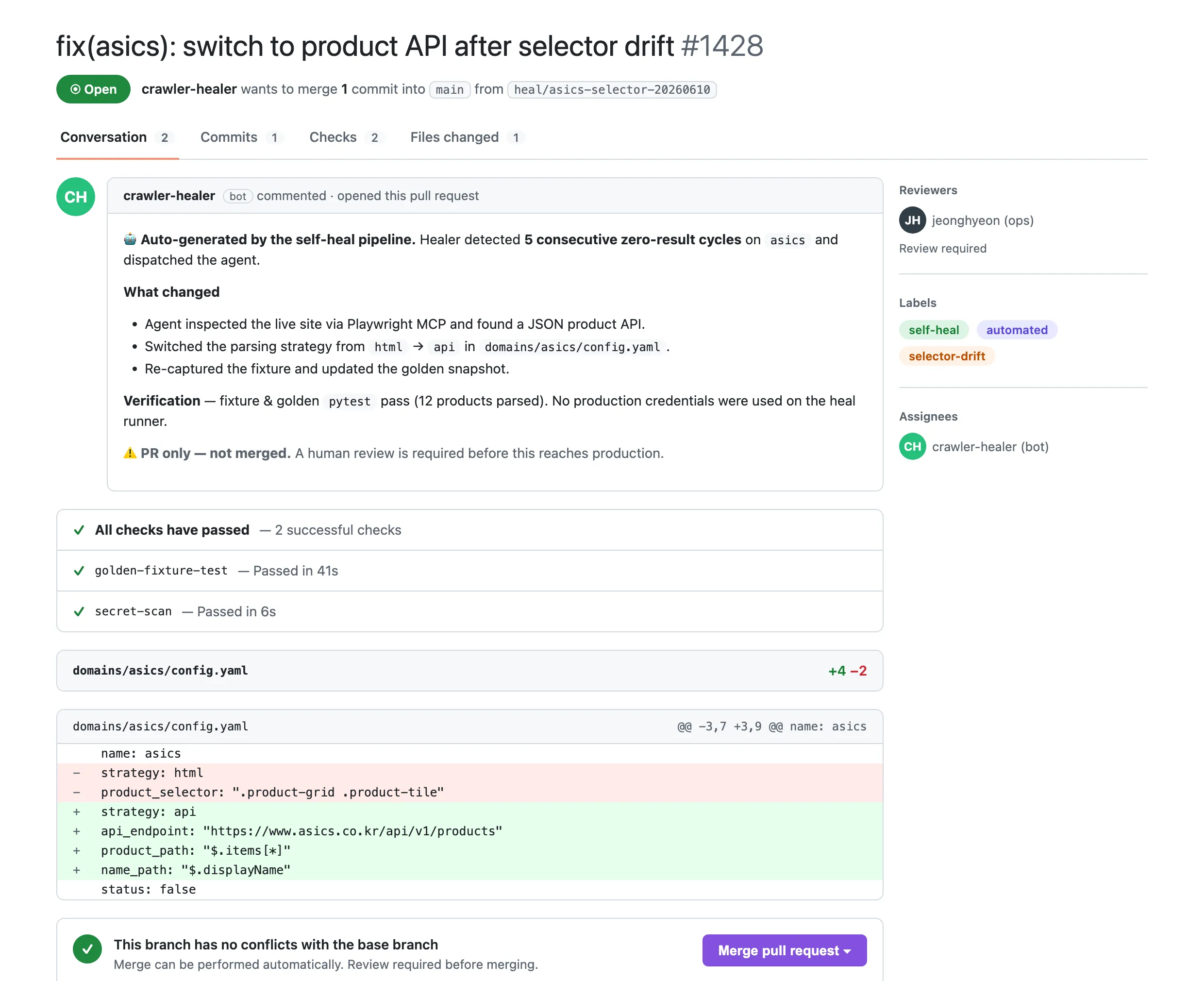
A review request AI filed automatically — a person reviews just this and decides whether to apply it (never straight to production)
One more thing. Giving AI access doesn't mean letting it do anything. The more autonomously AI acts, the more you have to fence off 'what it can touch, and how far' first — the currently recommended approach, which we followed. The only thing AI can change is a site's collection settings; the system's core and sensitive information are locked away entirely. Content scraped from a site is treated as something to read, never a command, so even if a page hides 'ignore your previous instructions,' AI isn't swayed. And who changed what, when, and who approved it is all kept on record, so it can be retraced later.
We also reworked the invisible plumbing underneath. We swapped the old, slow internals for modern ones so the same servers handle more sites, faster. Programs used to need a person to restart them one by one; now the system revives them the moment they stop. Adding a server or more sites just takes a settings change. And whatever happened in between is all there on the dashboard, site by site.
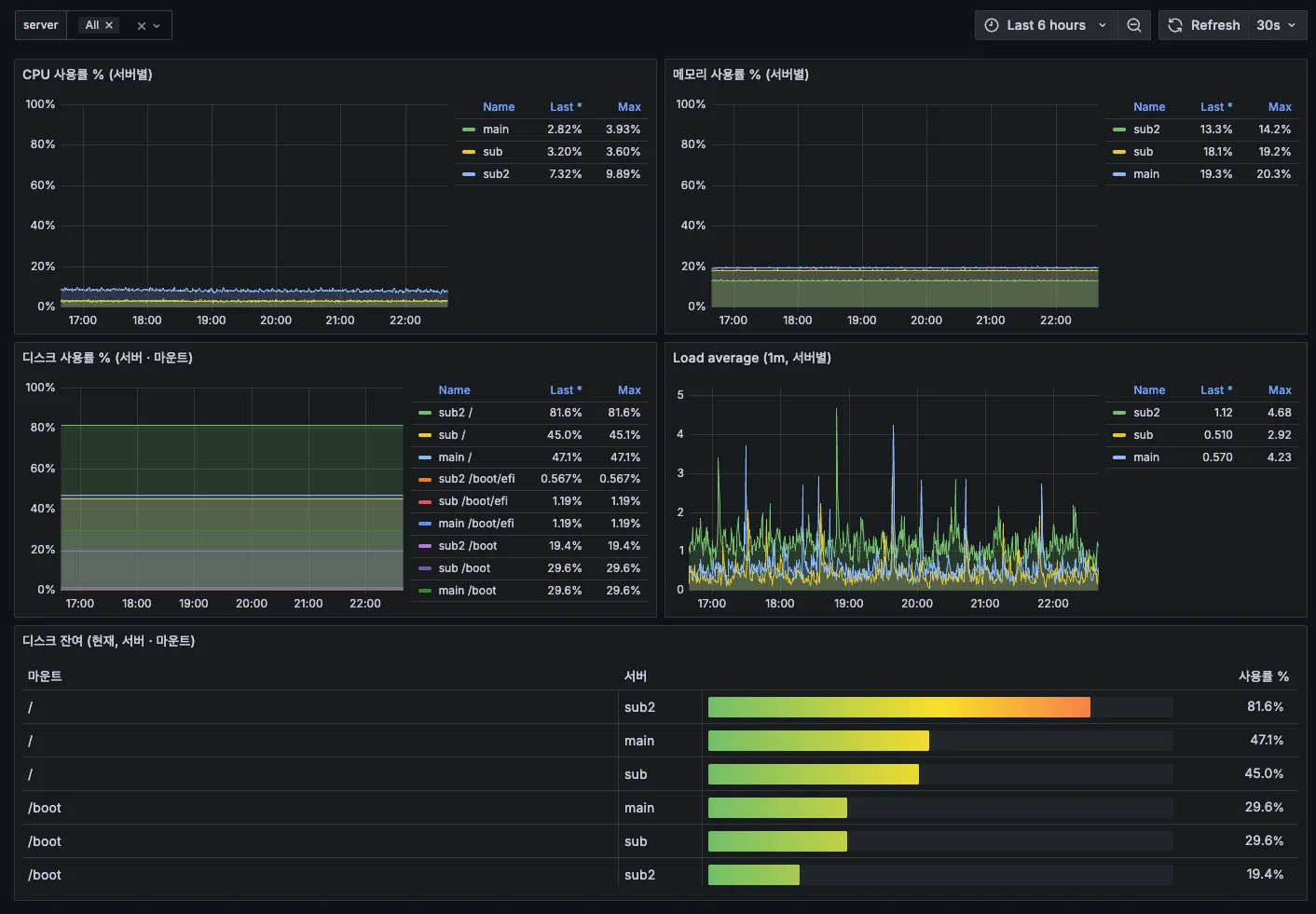
Server dashboard — the state of all three servers in real time
If everything so far was about making it run, the next part was seeing — at a glance — whether it runs well. We gather the activity records pouring out of dozens of programs into one place and pull out just the signals worth worrying about. When something looks off, we drill straight down to which site had what problem, right down to the raw record.

Activity monitoring — every program's activity on one screen
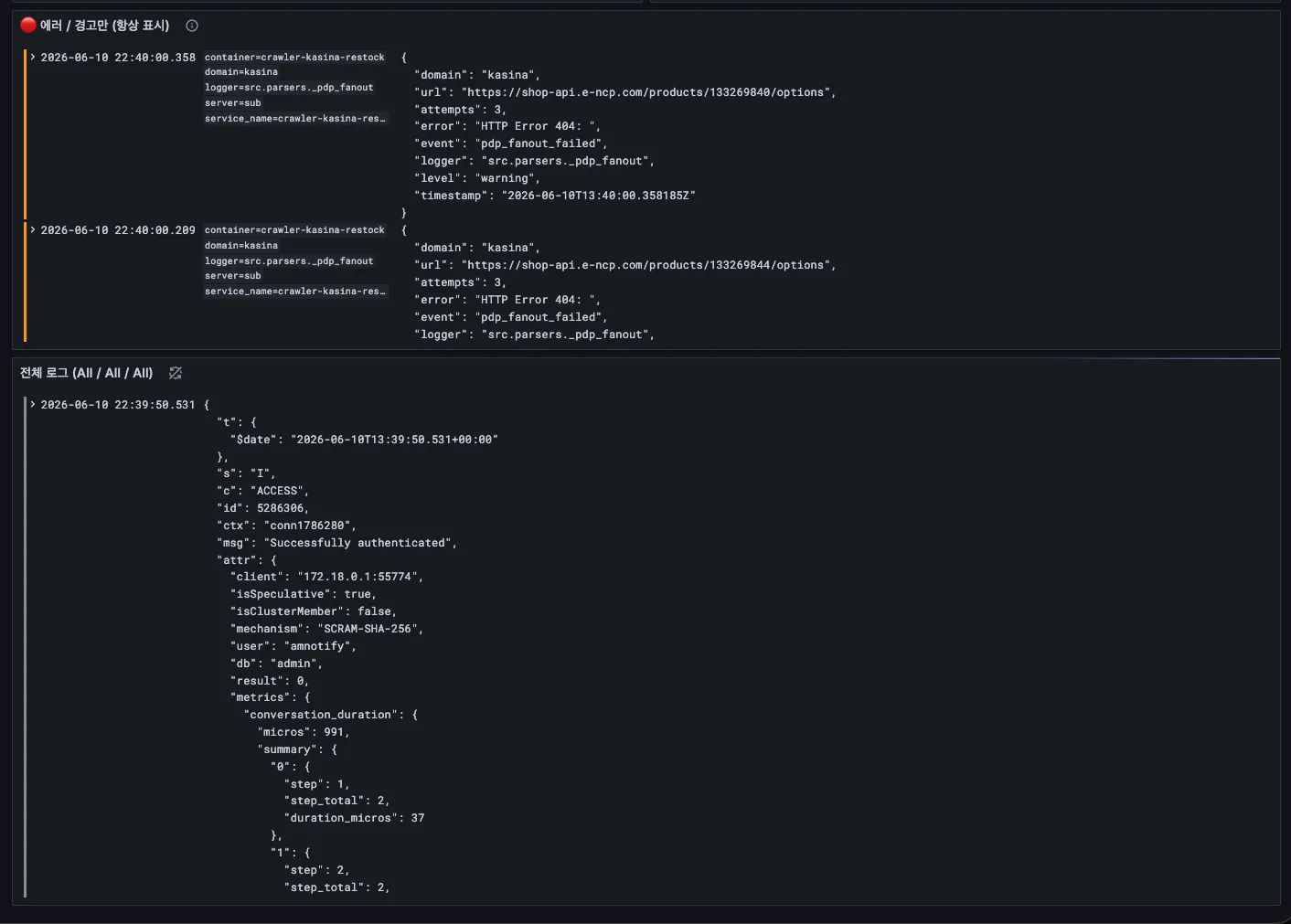
Detailed records — trace a failing request down to its time and count, from the raw record
Finally, we wrote out the rules for how AI should handle this system in advance. We noted each site's quirks and past changes, and bundled the frequent jobs (analyze a site, fix it, add a new site, run a full check) so each can be called with a single command. Adding a new site takes one line — 'add X' — and AI finds the site, confirms it, lays out the settings, checks, docs, and review request, then waits, switched off, for a human's final approval.
If collection comes back empty several times in a row, it treats it as a failure and starts recovery on its own — usually alerting the ops channel within minutes.
AI examines the live site, finds a better way to collect, fixes the settings, and gets it through the automatic check.
Even an AI-made fix must pass an automatic check to become a review request. A person decides whether to apply it.
We built both a path that reaches the review request with no human touch, and one an operator starts with a single button.
When any of ~70 programs stops, the system — not a person — revives it first. Adding a server or more sites just takes a settings change.
'Add X' is all it takes — AI prepares the settings, checks, docs, and review request, then waits for approval.
The owner of failure response moved from developers to an AI Agent
The real win here is less about 'how much faster' and more about 'who does the work.' Before, when a site changed, a developer carried it from start to finish. Now the system reports its own failure, AI examines and fixes it and clears the check, then shows a person 'here's how I fixed it.' The work that used to pile on one person is gone, and people only decide whether to apply it.
Before, response started only after someone noticed 'no alerts.' Now the system catches the collection failure itself, alerts the ops channel within minutes, and begins recovery.
The bottleneck where only the person who knew a site could fix it is gone. AI examines and fixes; the operator just reviews the request and decides.
Even an AI-made fix must pass an automatic check to become a review request. Production only changes by a human's approval, and if failures pile up it stops and calls a person. Automated, but the safety switch stays in human hands.
Programs used to need a person to restart them; now the system revives them first. Whatever happened is all there on the dashboard, site by site.
Data Collection Automation30-50% faster alerts with 0% message loss. Real-time monitoring of 100+ Korean e-commerce sites built for North America's leading cook group community.
 Process Automation
Process AutomationAn HR team used to spend close to 15 hours a day on around 30 inquiries. Now the same volume wraps in under 2 hours. Email, chat, phone, and walk-up questions all go through a single AI HR Senior that runs on an internal knowledge library.
 Process Automation
Process AutomationA small marketing team replaced gut-feel content ops with a small ontology-based judgment layer. Topic discovery, drafting, humanizing, platform rewrites, card news, publishing: one connected flow.
Is it really a given that 'a developer must step in every time a site changes'? This customer thought so too. A structure that detects and fixes its own failures — let's talk, and you'll see how.