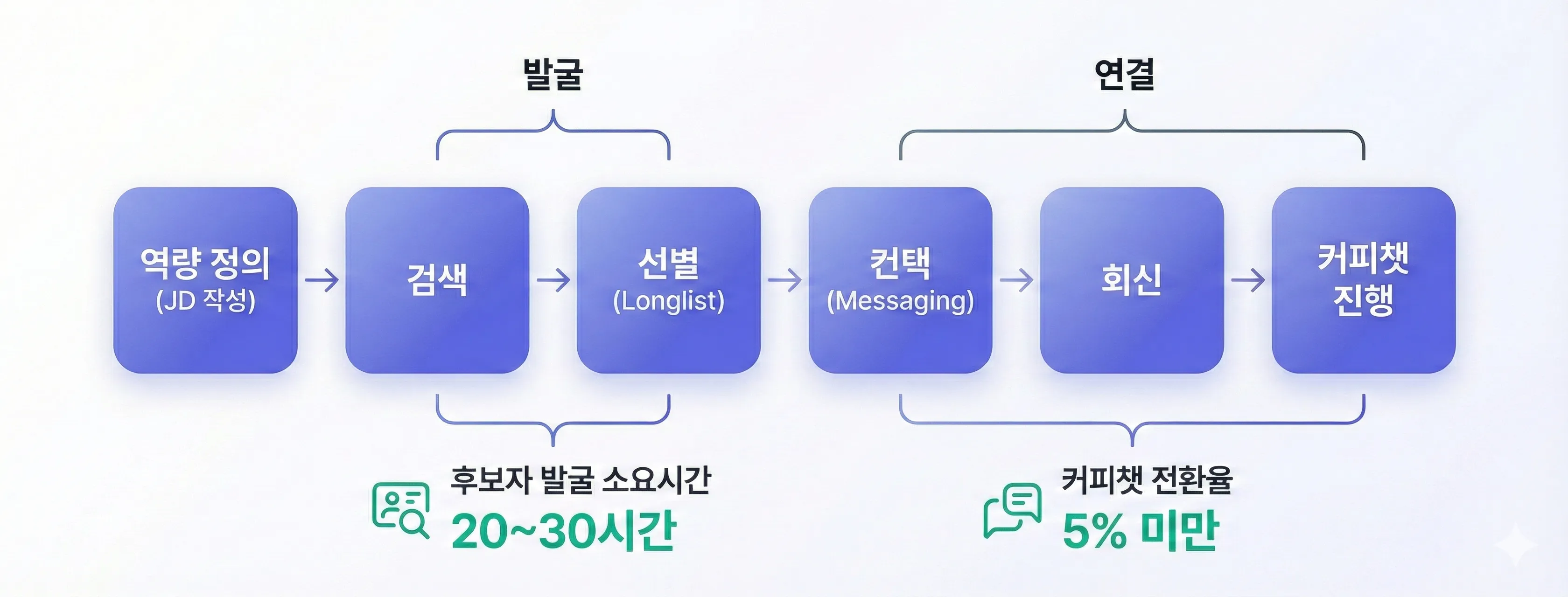
 업무 프로세스 자동화
업무 프로세스 자동화직원 전부가 조금씩 시간 뺏기고, 한 명은 아예 거기 매몰돼 있었어요
내부 문의 응대 시간 90% 감소, 평균 3초 응답 달성. 국가기관 규정과 도메인 지식 기반의 인하우스 AI 챗봇으로 보안 추적까지 확보한 사례
다이렉트 소싱 전 과정을 AI로 자동화하여, 소싱 시간 20시간→2시간, 리스트 자동화율 90%+, 커피챗 전환율 5배 상승을 달성한 AI 헤드헌터 구축 사례
채용 담당자 1~2명이 감당해야 하는 다이렉트 소싱의 현실
이 고객사는 AI 기반 채용 솔루션을 만드는 HR테크 스타트업입니다. 고객사들이 한결같이 같은 이야기를 했어요. 시니어·리드급 핵심 인재를 뽑고 싶은데, 채용 담당자 1~2명이 링크드인부터 깃허브, 블로그까지 뒤지며 후보를 찾느라 몇 주를 보내고 있다고요. 그렇게 찾아서 연락해도 답장 오는 사람은 거의 없었습니다.
“TA 담당자분이 그러시더라고요. '한 포지션에 20시간을 쏟아도 커피챗까지 가는 건 2건이 고작이에요. 프로필 200개를 봐도 연락할 만한 사람은 5명도 안 되고, 그 5명한테 연락해도 답장 오는 건 1명이면 다행이고요. 이러다 3개월 넘게 포지션이 안 닫혀요.' 이 얘기를 듣고 나서, 우리가 뭘 만들어야 하는지 확실해졌어요.”
— HR테크 스타트업 대표
현업이 '이 사람이다' 하는 감각을 시스템에 옮기기까지
고객사가 원한 건 인재 검색 엔진이 아니었습니다. 현업 리더가 프로필을 보고 '이 사람이면 되겠다'고 판단하는 그 과정을 시스템에 담고 싶어 했어요. 인재 정의부터 발굴, 평가, 메시지, 커피챗 전환까지 — 소싱 전체를 자동화하는 프로젝트였습니다.
다이렉트 소싱이란, 채용 공고를 올리고 지원자를 기다리는 게 아니라 기업이 직접 인재를 찾아 연락하는 방식입니다. 특히 시니어·리드급 핵심 인재는 이직 시장에 잘 나오지 않기 때문에, 기업이 먼저 다가가는 수밖에 없어요.
문제는 이 과정이 전부 수작업이라는 겁니다. 링크드인 검색, 프로필 분석, 역량 판단, 메시지 작성, 일정 조율까지. 아래 이미지는 이 프로젝트에서 자동화한 다이렉트 소싱 파이프라인의 전체 흐름이에요.
멀티플랫폼 데이터 수집부터 AI 평가, 자동 아웃리치까지의 전체 파이프라인
이 파이프라인이 최종적으로 어떤 모습으로 동작하는지, 실제 SaaS 플랫폼 시연 영상을 먼저 확인해보세요. 채팅 인터페이스에서 포지션 정의부터 후보 탐색, 평가, 컨택까지 원스톱으로 진행되는 구조입니다.
B2B 리스트 제공에서 셀프 소싱 SaaS 플랫폼으로 진화한 모습
첫 미팅은 고객사 사무실이 아니라, 실제로 채용에 고통받는 기업의 TA 팀 옆에서 시작했습니다. 채용 담당자가 아침부터 링크드인에서 프로필을 하나씩 열어보고, 엑셀에 이름과 경력을 옮겨 적는 모습을 관찰했어요.
그러다 현업 리더한테 "어떤 사람을 원하세요?"라고 물으니, JD에 없는 이야기가 쏟아졌습니다. "대규모 트래픽을 한 번이라도 직접 겪어본 사람이요. 매뉴얼대로 하는 사람 말고, 장애 상황에서 스스로 판단할 수 있는 사람." 이런 맥락은 JD 어디에도 없었어요. 그 격차를 메우는 게 이 프로젝트의 시작점이었습니다.
가장 먼저 만든 건 'Role 정의 엔진'이었어요. 현업 리더가 자연어로 기대치를 입력하면, AI가 Must-have·Nice-to-have·Risk로 분해합니다.
"입사 후 6개월 안에 이 문제를 해결해야 한다"를 넣으면 '분산 시스템 운영 경험 3년+', '오픈소스 기여 이력', '매니지먼트만 하고 핸즈온 부재 리스크' 같은 항목이 나와요. 각 항목을 검증할 수 있는 '실력 신호'까지 정의합니다. '대규모 트래픽 경험'이 구체적으로 어떤 프로젝트·어떤 지표로 확인 가능한지까지요.
현업 리더 머릿속에만 있던 '좋은 사람의 기준'이 처음으로 문서로 잡히는 순간이었어요.
이 엔진이 제대로 된 기준을 뽑아내려면, 프롬프트 하나를 감으로 쓸 수가 없었어요. Chain-of-Thought, Few-shot, Negative prompt 등을 조합해서 100가지 이상의 프롬프트 변형을 자동 생성하고, 인하우스 채용 전문가 팀이 각 결과를 정성 평가하는 체계를 만들었습니다. 가장 높은 정확도를 보인 조합을 선정해서 시스템에 반영했어요.
다음은 후보 발굴이었는데, 여기서 가장 큰 기술적 도전을 만났습니다. 좋은 사람은 한 곳에 모여 있지 않아요. 링크드인 프로필, 깃허브 커밋, 기술 블로그, 컨퍼런스 발표, 오픈소스 기여 내역이 전부 다른 플랫폼에 흩어져 있습니다.
단순히 데이터를 모으는 것만으로는 안 됐어요. 핵심은 '역량 메타데이터 증강'이었습니다.
흩어진 데이터를 하나의 후보 프로필로 엮고, 그 위에 역량 신호를 덧씌우는 거예요. 깃허브에서 어떤 규모의 프로젝트에 얼마나 기여했는지, 블로그에서 어떤 깊이의 기술 이야기를 하는지. 이런 파편을 엮으면 이력서만 봤을 때는 안 보이던 역량이 드러납니다.
← 좌우로 스크롤하여 차트를 확인하세요
다이렉트 소싱 자동화 파이프라인 전체 흐름
데이터를 모으고 나면, 진짜 어려운 문제가 시작됩니다. LLM 기반 추론 시스템으로 후보를 평가하려면, AI가 '이 사람이 언제 어디서 무엇을 했는지'를 정확히 이해해야 합니다.
그런데 LLM에는 시간 개념이 약합니다. 실제 재직기간이 2020~2022년인데, 그 회사가 2018~2020년에 발표한 보도자료를 근거로 판단하는 일이 반복됐어요. 학계에서도 검증된 문제였습니다.
이걸 해결하려면 RAG(Retrieval-Augmented Generation) 파이프라인 자체를 손봐야 했어요. 임베딩에 재직 시작·종료 시점, 시간 버킷 같은 시계열 메타데이터를 붙이고, 검색 단계에서 '요청한 재직 구간과 겹치는 청크만' 반환하도록 강제 필터를 걸었습니다. 이렇게 하니까 재직기간과 무관한 시대의 데이터를 근거로 답변하는 사례가 사라졌어요.
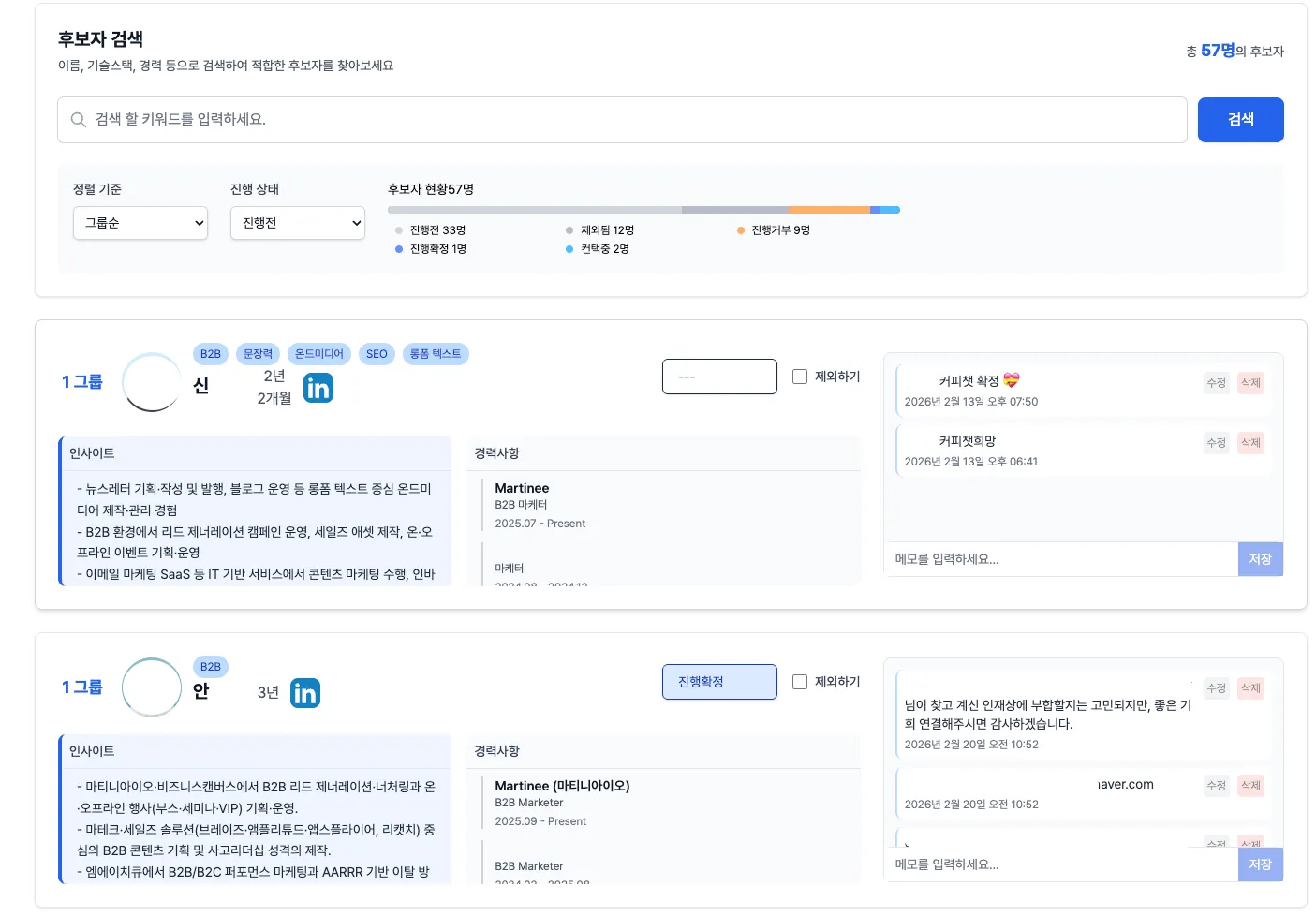
LLM + RAG 기반 추론 시스템이 생성한 인재 쇼트리스트 대시보드
시계열 문제를 잡았더니, 이번엔 Context 한계에 부딪혔습니다. 후보의 역량 태그가 늘어날수록, 각 태그에 대한 근거 문맥이 비선형적으로 증가했어요. 상용 모델의 컨텍스트 제한을 초과하는 경우가 빈번했습니다.
세 가지로 풀었어요. 첫째, 태그 단위로 쿼리를 분해해서 병렬로 리트리벌을 수행했습니다. 둘째, 뉴스 기사처럼 본문이 길고 반복이 많은 데이터는 LLM으로 핵심 문장·키워드만 압축한 뒤 임베딩에 활용했어요. 셋째, 질의를 프롬프트 말미에 배치해서 'Lost in the Middle' 현상을 완화했습니다.
여기에 멀티 모델 앙상블까지 도입했어요. 한 모델이 추론하면 다른 모델이 교차 검증하는 구조입니다. 단일 모델의 환각이나 편향을 걸러내서, 현업 리더가 'AI가 왜 이렇게 판단했는지' 납득할 수 있는 결과가 나오게 됐습니다.
← 좌우로 스크롤하여 차트를 확인하세요
멀티 모델 앙상블 교차 검증 아키텍처
후보를 모으는 건 공학 문제지만, 후보를 '판단'하는 건 다릅니다. 현업 리더가 프로필 보고 10초 만에 '이 사람은 아니야'라고 하는 그 직관을 AI에 담아야 했어요. 단순 키워드 매칭으로는 안 됩니다. '파이썬 5년'이라고 적혀 있다고 좋은 백엔드 엔지니어가 아니니까요.
우리가 만든 건 '업무 수행 가능성 추론 엔진'입니다. 루브릭의 각 항목에 대해, 후보의 공개 데이터에서 수집한 근거를 매핑하고, 점수와 요약을 동시에 생성합니다.
'이 후보는 분산 시스템 경험이 있는가?' → '쿠버네티스 기반 마이크로서비스 프로젝트에 2년간 주요 커미터로 기여, 대규모 트래픽 대응 사례 블로그 3건 작성.' 이렇게 근거가 붙는 평가입니다.
모든 의사결정에 '왜'가 기록되도록 설계했어요. 왜 이 후보가 쇼트리스트에 올라갔는지, 왜 저 후보가 제외됐는지. 자동화했다고 하면 의심부터 하는 현업한테, 판단 근거를 직접 보여줄 수 있어야 했거든요.
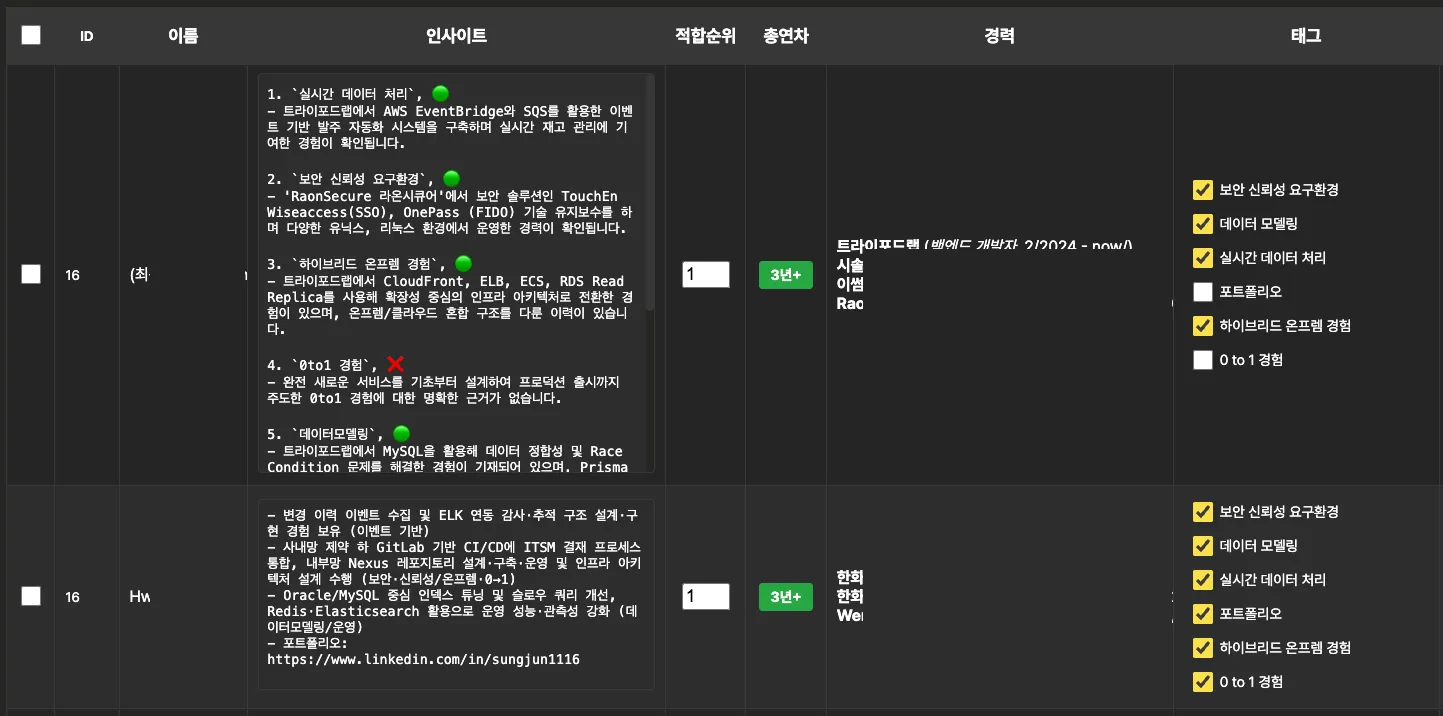
각 후보에 대해 '왜 이 사람인지' 근거가 붙는 AI 평가 리포트
쇼트리스트가 나와도, 후보가 만나주지 않으면 소용없습니다. 템플릿 메시지의 회신률은 보통 5% 미만이에요. 95%의 노력이 허공에 날아가는 거죠.
그래서 초개인화 메시지 엔진을 만들었어요. 후보의 공개 활동 데이터를 기반으로 '왜 당신인지'(이 후보만의 강점을 언급)와 '왜 지금인지'(이 팀이 지금 이 포지션을 여는 맥락)가 자연스럽게 들어간 메시지를 자동으로 생성합니다.
"최근 올리신 분산 트레이싱 블로그 글을 인상 깊게 봤습니다. 저희 팀이 지금 정확히 그 문제를 겪고 있어서요." 이런 수준의 메시지를 후보 30명분, 20~30분이면 끝납니다.
회신 후에는 자동 전환 파이프라인이 작동해요. 가능한 일정 후보 제안, 커피챗 직전에 현업 리더한테 자동 공유되는 후보 요약 1페이지까지. 후보 입장에서는 '이 팀 준비 잘 하네'라는 인상을 받고, 현업 입장에서는 10분 만에 이 후보가 왜 좋은지 파악할 수 있게 됩니다.
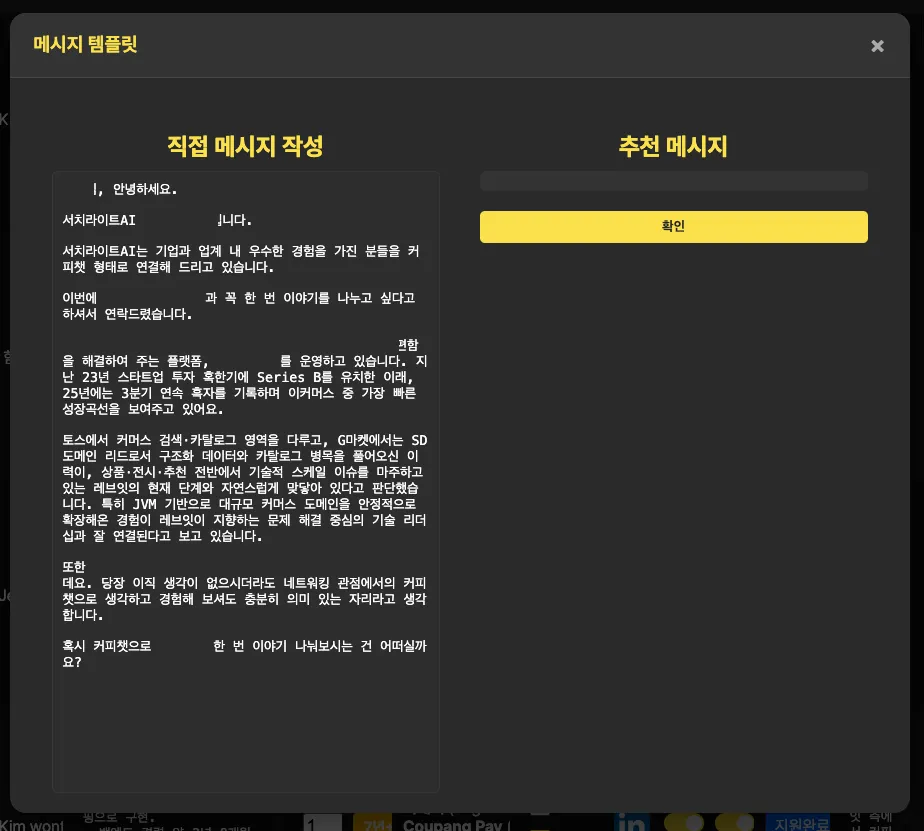
후보의 공개 활동을 기반으로 자동 생성된 초개인화 메시지
검색·선별을 자동화한 뒤, 고객사가 다음으로 확장한 영역은 '후보와의 실제 연결'이었습니다. 처음에는 B2B 형태로 쇼트리스트를 만들어서 전달하는 모델이었는데, 수요가 늘면서 고객사 스스로 소싱을 돌릴 수 있는 SaaS 도구로 전환하기 시작했어요. 채팅 인터페이스처럼 직관적인 화면에서 포지션 정의부터 후보 탐색, 평가, 컨택까지 원스톱으로 진행할 수 있는 구조입니다. 검증된 AI 파이프라인 위에 사용자 경험을 올린 거예요.
100가지 이상의 프롬프트 조합 실험을 거쳐 최적화된 추출 정확도를 확보했어요. 현업 리더의 자연어 입력이 Must-have·Nice-to-have·Risk로 자동 구조화됩니다.
여러 플랫폼에 흩어진 후보의 활동 데이터를 하나로 엮고, 역량 신호를 증강합니다. 이력서에 없는 역량이 드러나요.
임베딩에 재직 시점·종료 시점 메타데이터를 붙이고, 검색 단계에서 시간 기반 필터를 강제합니다. LLM이 잘못된 시대의 데이터를 참조하는 문제를 원천 차단해요.
한 모델이 역량을 추론하면 다른 모델이 교차 검증합니다. 단일 모델의 환각과 편향을 걸러내서, 사람이 검토해도 고개를 끄덕일 수 있는 결과가 나와요.
후보별로 '이 사람이 우리 문제를 풀 수 있는 이유'를 요약합니다. 공개 데이터에서 찾은 프로젝트·기여·글이 근거로 들어가요.
왜 이 후보가 올라갔는지, 왜 제외됐는지 모든 의사결정에 이유가 붙습니다. '왜?'라고 물으면 바로 답이 나오는 구조입니다.
후보의 공개 활동 기반으로 '왜 당신인지'와 '왜 지금인지'가 담긴 메시지를 자동 생성합니다. 30명분 20~30분이면 끝나요.
회신 후 일정 제안, 후보 요약 자동 공유, 피드백 수집까지. 관심 표현부터 실제 만남까지의 시간을 줄여줍니다.
링크드인 검색 대신, 후보가 왜 좋은지 이야기하는 데 시간을 씁니다
시스템이 돌아가기 시작한 뒤, 실제로 이 플랫폼을 쓰는 기업들의 변화가 전해졌습니다. "TA 담당자가 이제 아침에 링크드인부터 열지 않아요. 대신 AI가 만든 쇼트리스트를 검토하고, 현업 리더랑 '이 후보의 이 경험이 우리한테 왜 중요한지' 대화하는 데 시간을 씁니다." 단순히 빨라진 게 아니라, TA 담당자가 하는 일 자체가 바뀐 거예요.
이전에는 하루가 링크드인 검색과 엑셀 정리로 시작했습니다. 이제는 AI가 만든 쇼트리스트를 검토하고, 현업 리더와 '이 후보의 어떤 점이 우리 팀에 맞는지' 논의하는 걸로 하루가 시작돼요. 검색하는 사람에서 판단하는 사람으로, 역할 자체가 바뀐 거예요.
예전엔 현업한테 '이 프로필 좀 봐주세요'가 스트레스였어요. 수십 명의 프로필을 언제 다 봐요. 이제 AI가 근거와 함께 5~10명 쇼트리스트를 주니까, 현업 리더가 10분 만에 의미 있는 피드백을 줍니다. 채용이 HR만의 일이 아니라 팀의 일이 되는 시작점이었어요.
템플릿 메시지 시절 회신률이 5% 미만이었는데, 초개인화 메시지로 바뀌면서 눈에 띄게 올랐습니다. 후보들이 '제 블로그 글까지 보셨어요?'라고 놀라면서 회신하는 경우가 생겼어요. 연락 자체가 스팸에서 의미 있는 제안으로 바뀐 겁니다.
처음엔 저희가 쇼트리스트를 만들어서 전달하는 B2B 모델이었습니다. 시스템이 안정화되면서 고객이 직접 소싱을 돌릴 수 있는 SaaS 도구로 전환했어요. 채팅 인터페이스처럼 직관적인 화면에서 포지션 정의부터 컨택까지 원스톱으로 됩니다. 이미 검증된 기술 위에 쓰기 편한 도구를 얹은 거예요.
커피챗 이후 피드백 — 왜 진행했는지, 왜 안 했는지 — 이 시스템에 쌓이면서 다음 소싱의 평가 기준과 메시지 전략이 자동으로 보정됩니다. 3개월 전보다 6개월 후의 쇼트리스트 품질이 눈에 띄게 좋아져요.
“'AI가 사람을 판단한다고요?' 처음엔 그 반응이었어요. 채용은 결국 사람이 봐야 하는 영역이라 생각했거든요. 근데 OTOworks가 저희 고객사 TA 팀 옆에서 실제 업무를 뜯어보면서 만든 걸 보니, 감이라고 여겼던 게 사실은 패턴이더라고요. 결정적이었던 건, 추천마다 '왜 이 사람인지'가 달려 나온다는 거예요. 프로필 수십 개 던져놓고 '한번 봐주세요'가 아니라, 이 사람의 이 경험이 왜 맞는지가 정리돼서 오니까 현업이 진짜 움직여요.”
HR테크 스타트업 대표대표
업무 프로세스 자동화내부 문의 응대 시간 90% 감소, 평균 3초 응답 달성. 국가기관 규정과 도메인 지식 기반의 인하우스 AI 챗봇으로 보안 추적까지 확보한 사례
 PC 자동화
PC 자동화30분 걸리던 EBS 시험지 다운로드를 1분으로 단축하고 클릭 50회를 3회로 줄인 대치동 학원 강사님의 업무 자동화 도입 사례입니다.
 문서 자동화
문서 자동화12시간 걸리던 문서 분류를 7분으로 단축하고 98% 정확도를 달성한 AI 자동 분류 도입 사례. 전문 평가 업무에 온전히 집중하세요.